

Variables
Foreword
No matter the type of job, we almost always need some form of storage. Chefs need their walk-ins and knife drawers. Mechanics need their toolboxes. Accountants use filing cabinets (physical and electronic). Software developers also require storage. When our code is running, we need memory locations to temporarily store data. Variables provide that storage. In the final section of this chapter, identifier naming rules and conventions are reviewed.
Variables - A Closer Look
In Python, a variable is a location in memory (on the stack) that holds a reference to an object. The 'stack' is static memory set by the bytecode compiler. The stack is also known as 'local storage'. More on this below.
Conversely, values of the variables are stored on the 'heap' which is dynamic memory managed by the PVM or JIT compiler depending on whether CPython or PyPy is the implementation. The heap is also known as 'free storage'. More on this below.
All variables in Python reference objects. Each variable is an address location on the stack and it holds a reference (address) to the actual storage location in memory where the value is stored. This method of variable storage is different than that employed in some other languages. For instance in C++, for primitive variables like integers and floats, the variable location actually stores the value and not a reference to the value.
These are some relevant points about variables in Python:
- Variables (the references to the actual values) and the values to which they point are both stored in RAM (random access memory).
- Variables (the references) are stored on the program stack (a.k.a. local storage).
- Values are stored on the program heap (a.k.a. free storage).
- Variable values, the data stored at a location in memory, can change while the program is running.
- The data type to which a variable references can change. This is dynamic-typing discussed in the Introduction to Python chapter.
- If two variables contain the same value and are in the same scope they point to the same object in memory (more on this in the Functions chapter).
- When a variable goes out of scope it is marked as ready for deletion and will be reclaimed by the garbage collector process of the PVM.
- When a program exits, all references to the program's variable data are lost and the memory is released back to the operating system.
- Variables created inside a function have scope which is local to that function. This means that those variables are not visible from and cannot be used outside of that function. This is known as function-level scope.
- Variables in some languages like C++, C#, and Java have block-level scope. Python uses function-level scope which means variable visibility is limited to the function containing the variable. If a variable is not in any function, it is visible within the entire module. PHP, Python, and Javascript also use function-level scope.
- Variables created outside of all functions have module-level or global scope and are visible to all code in that module.
How do we refer to or access the contents of a variable? Well, we could use the hexadecimal address of the variable's location in RAM, something like: 0x74adf8b0. That's a hexadecimal number representing a real 32-bit address . Count the hex numbers 7...0 and you will notice there are eight. Each hex number represents four bits and there are eight hex numbers so: 8 x 4 = 32 bits.
Using hex numbers to identify locations in memory would be onerous, time-consuming, and error prone. The solution: give variables more humanly recognizable names. For instance, aircraft_range and aircraft_weight could be variables to store the distance an aircraft could fly and its current weight. We could use the words aircraft_range and aircraft_weight to identify that data. Therefore, aircraft_range and aircraft_weight would be identifiers, the names of the variables.
Identifiers provide a convenient means to identify variables which is much nicer than using hexadecimal addresses. An identifier is a name for a variable, function, module, class, or any other object. Internally, to the PVM, the identifiers aircraft_range and aircraft_weight might be equivalent to the memory addresses: 0x93acf7b4 and 0x93acf8a9. In other words, those are the locations in memory where the values for aircraft_range and aircraft_weight are stored. Fortunately, we use the identifiers instead of the hex addresses to access the variables.
Variables - Code Examples
Let's now consider a code example and follow how the relationships between variables and objects work. Notice a new program named variablestoobjects.py is displayed. Recall that you don't have to create a new project for each new .py file. All of the code for this class can be contained within one project.
Lines 1 - 4 demonstrate the creation of four variables of different datatypes. And, each of the variables is initialized by using the '=' and a value. The '=' is known as the assignment operator. A variable is initialized the first time it is assigned a value. Again, the '=' is known as the assignment operator. It assigns values on the right to variables on the left. Variables on the left are also known as 'lvalues'. The 'l' represents a location in memory. To assign something to the right of the '=' to something on the left, the item on the left must have a name and be a storage location.
On line 1, the variable 'name' is assigned the value of a string object which contains 'Zena'. The identifier of the variable is 'name'. On line 2 age is assigned the integer 7. Therefore, age will reference the object 7. Line 3 assigns the boolean value of 'True' to the variable 'loves_pi'. And on line 4, the variable 'pi' is assigned the floating point (type float) value of 3.14159. The print statement on lines 5 and 6 display the contents of the variables. The variables are converted to strings using the built-in function str() which returns a printable string.
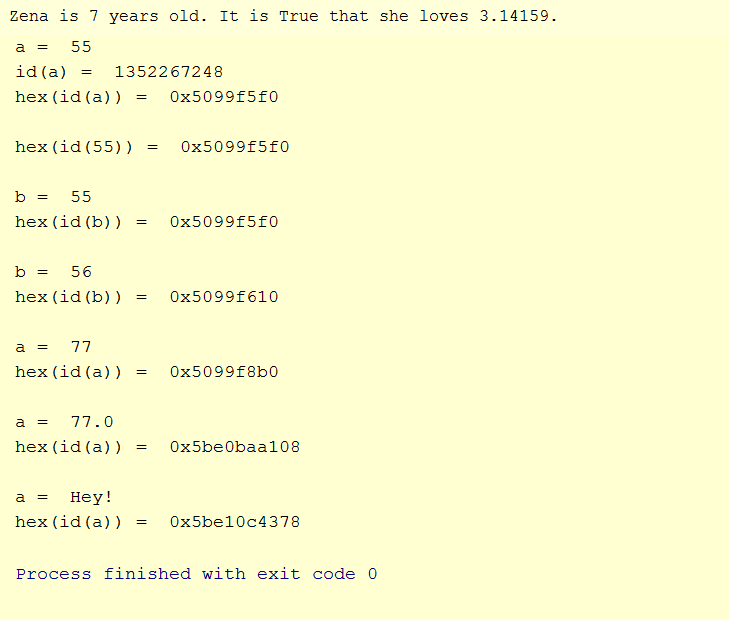
The purpose of lines 8 - 33 is to demonstrate how variables reference objects in Python. Keeping track of variable references and object addresses is not something Python developers normally do. However, you should have at least a minimal understanding of the process so it not mysterious if the need for additional investigation is required. Furthermore, some languages (e.g. Java) have similar memory management strategies while others (e.g. C/C++) have a considerably different approaches. By understanding how it works in Python, a developer should be more comfortable when working with memory models in other languages.
Lines 8, 15, 19, 23, 27, and 31 are simple assignment statements. On lines 8, 15, 19, and 23 integer values are assigned. In each of those cases, the variables reference (or point to) an integer object. Line 27 assigns a float type (a number that includes the decimal point). After line 27, the variable 'a' no longer references an integer value (lines 8 and 23) but now references a float (77.0). On line 31 the type to which 'a' points is changed again, from float to string.
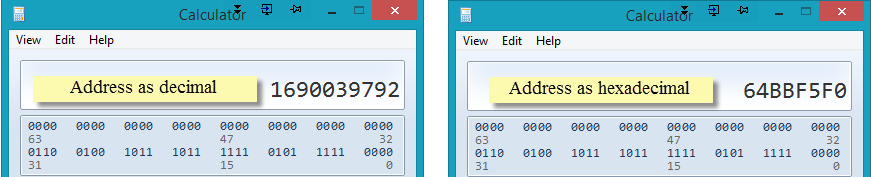
Now, let's take a look at the addresses to which the variables point. We use the built-in function id() to return the integer (or long integer if required) value of the address where the variable value is stored. Normally, computer scientists use hexadecimal values to work with addresses. Therefore, the built-in function hex() is used to convert the integral value returned by id() to a hex value. See the images of the calculator that were used to confirm that the integer and hexadecimal values are equivalent.
See the program output. The variable 'a' from line 5 is stored at hex address 5f0 (shortened to last three characters). Notice that line 13 shows the location of the numeric literal object '55' and that is also stored at location 5f0. The variable 'a' points to the object '55'. Note that when variable 'b' is assigned '55' it also points to 5f0. However, the address to which 'b' points changes to 610 when it is assigned the object '56'. When 'a' is assigned '77' the address to which it points is changed to 8b0. On line 27, 'a' is assigned the value '77.0' which is a floating point number (a float type that contains a decimal). The address to which 'a' points is changed again to 108. Finally, 'a' is assigned the string value of 'Hey!' and the reference now points to 1f0.
The value of 'a' is changed three times. Variables are called variables since the values that they reference can change (vary). Furthermore, the type of the value to which a variable points can also change. The type to which 'a' points was changed from integer, to float, and then to string.

Calculator comparison (be sure to set View | Programmer) - Confirm that the integer and hexadecimal values are equivalent. Also notice that the binary numbers are equivalent.
Here's the output.
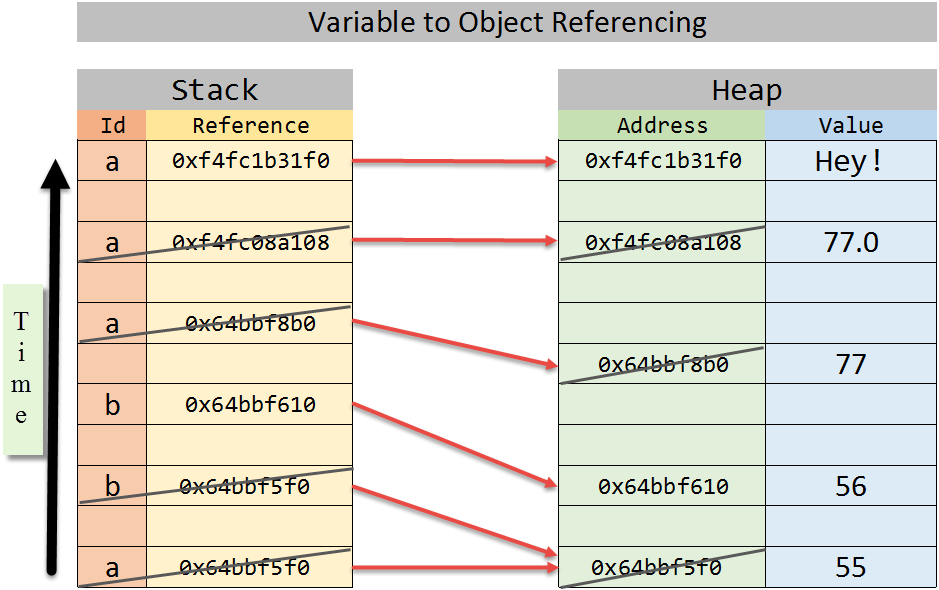
Variable to Object Referencing- Code Examples
Notice in the graphic below how the address references change as the variables are assigned new values. Read the diagram from the bottom-up and starting with the stack. In the stack on the left, the variables are loaded (pushed) onto the stack from the bottom-up - meaning the stack grows from the bottom-up over time. The crossed-through entries on the stack and heap are no longer active. The only active (live) variables near the end of the program are b = 56 and a = 'Hey!'. And, after the program exits, all stack and heap memory locations are released and can be reused by the operating system.
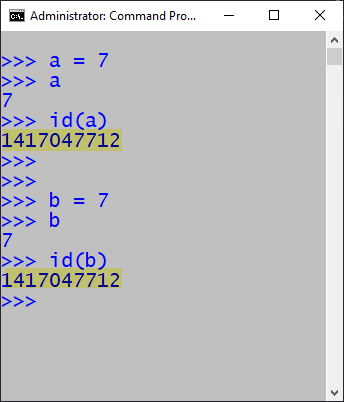
Command Line Interpreter Memory Management
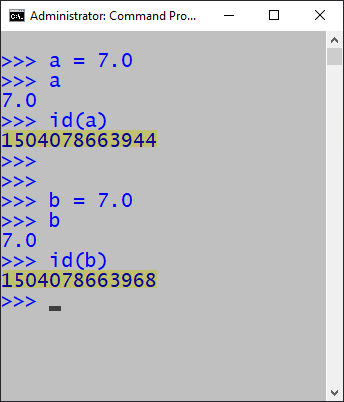
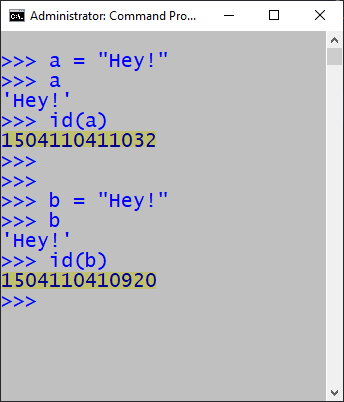
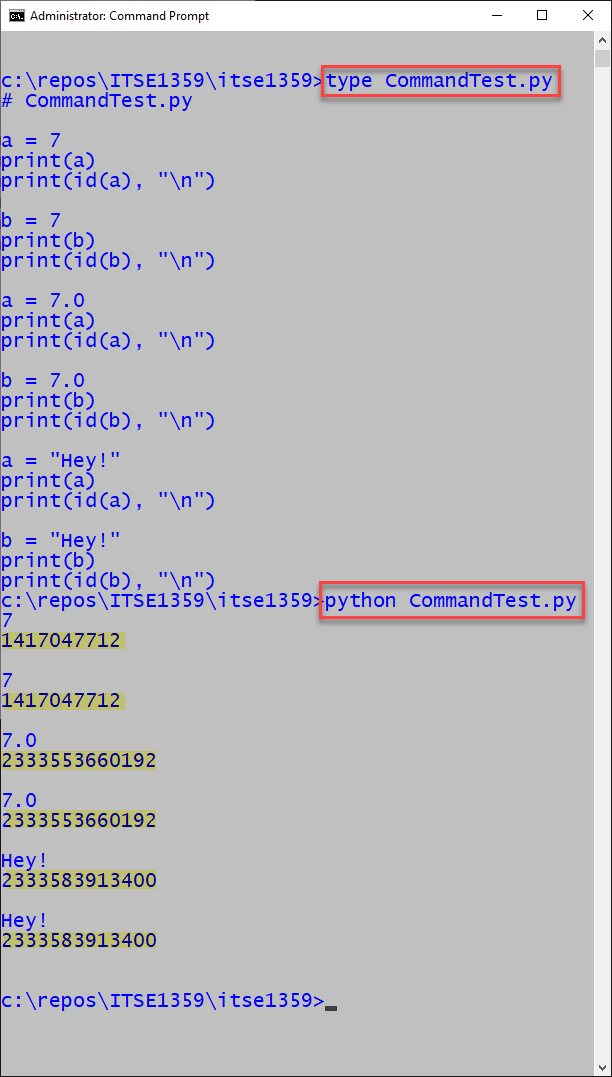
The interperter manages memory differently in command line interactive mode compared to command line script mode. The first examples below show integer, float, and string assignment are in command line interactive mode. Notice that only the integer assignment addresses are the same. On the other hand, when the same code is run in script mode, all data type pairs share addresses when containing the same value.
Command line interactive mode: integer variables share the addresses.
Command line interactive mode: float variables do NOT share the addresses.
Command line interactive mode: string variables do NOT share the addresses.
Command line script mode: all data type pairs share the addresses.
It should be noted that references are considered addresses in the CPython implementation (the default that ships from python.org). However, other Python implementations (interpreters) may not maintain the exact same one-to-one relationship between references and addresses. Furthermore, memory mangement will vary by implementation.
Identifier Naming Rules and Conventions
Python identifiers (names) have rules which govern their use and must be followed. There are also conventions that supply recommendations and should be applied if practicable.
Naming rules for Python identifiers must be followed or syntax errors will result.
- Cannot be a keyword (see table below)
- Must begin with a letter or underscore: _total_cost, weight_
- Can contain only letters, numbers, or underscores: num9_bike, route_66
- Are case sensitive: num1 is different from Num1
Naming Conventions for Python identifiers are recommended but not required.
- Class names use 'CapWords' (a.k.a Pascal Casing): BuildingLayout, RegionalEquipment
- Variables, methods, and function identifiers use all lowercase and underscores to separate words (a.k.a. snake_case): calculate_discount, compute_psi
- Avoid single letter names such as "i", "x", "a" except for counters or iterators
- Avoid using unclear characters such as: lowercase letter "l", the letter "o", uppercase letter "I"
Remember that code is read much more often than it is written. Therefore, do your best to write clear and readable code. To the extent practicable, make your code declarative (readable) and semantic (meaningful).
See more on naming rules and conventions here: PEP 8 (Python Enhancement Proposal) and Google Python Style Guide.
Keywords
The Python keywords (a.k.a. reserved words) are listed in the table below. Keywords are reserved by the language and cannot be used as identifiers.
| Keywords | ||||||||
| and | as | assert | break | class | ||||
| continue | def | del | elif | else | ||||
| except | False | finally | for | from | ||||
| global | if | import | in | is | ||||
| lambda | None | nonlocal | not | or | ||||
| pass | raise | return | True | try | ||||
| while | with | yield | ||||||