

Programming Fundamentals - part 2 of 2
Foreword
We continue our discussion of fundamentals of programming in this chapter by reviewing various code types from source to native. Then, compiled and interpreted languages are considered.
Types of Code
Source, Bytecode, Assembly, OpCode, Object, Machine, Native
When working with and studying a programming language, you will encounter various adjectives for code: source, bytecode, assembly, opcode, object, machine, and native. Let's define each of these terms. Since the concepts and terms may be new to you, it is imperative that you reread the material many times, take notes, and make your own note cards. A very active study approach is required for technical material like that found in this course.
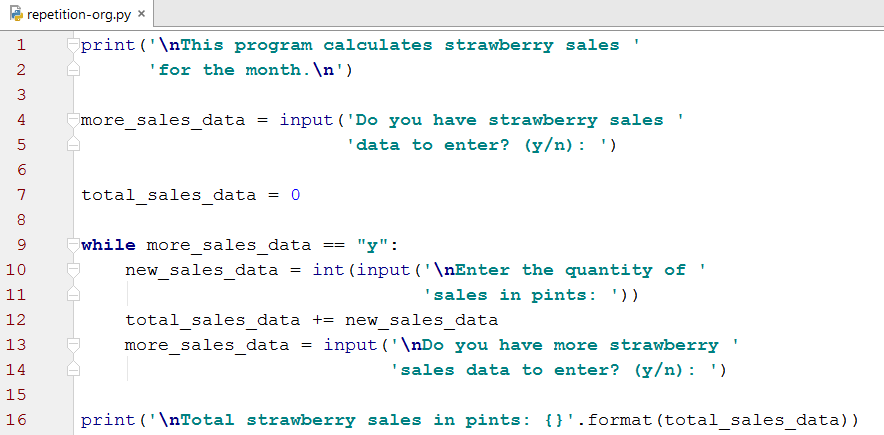
Source code - The code that most (non-assembly) programmers write. It is also referred to as 'high-level' since of all the computer code types it is the closest to human language. Even without programming experience, some of the meaning of source code can be derived simply by reading it. The example below is an elementary program written in Python source code.
Bytecode (a.k.a p-code or portable code) - Recall from the Introduction to Python chapter that in computer science, a compiler transforms code from one language to another. Also recall that the typical processing steps for Python are: IDE (source code) -> Bytecode Compiler (converts source code to bytecode) -> PVM (Interpreter - converts bytecode to machine code) -> CPU runs the machine code.

A bytecode-compiler reads source code and converts (compiles) the high-level source code into intermediate level bytecodes. Bytecodes have names (opnames) which are compact mnemonic codes like BINARY_ADD and LIST_APPEND. The opnames are for human readability and are not used internally for processing.
Bytecodes also have numbers (opcodes) like 01h, 12h, 17h, which are processed by the PVM (interpreter) or by a JIT compiler. The numeric code associated with bytecodes is referred to as the 'opcode' (see below). While bytecode opnames may look like machine code assembly instructions, they are not the same. Bytecode is run by the interpreter (PVM) whereas assembly code (symbolic machine code) is run directly on the CPU.
After creation, bytecode is processed in one of two general ways. See the diagram in the Introduction to Python chapter. The first and more common option is to use CPython, the implementation installed from python.org. When processed by an interpreter (Python virtual machine (PVM)), the bytecode is run directly, line-by-line as the program runs. The virtual machine executes the machine code corresponding to each bytecode. This is the standard way CPython operates.
Secondly, bytecode may be processed by a JIT Compiler and converted into machine code in bulk. That machine code is then run by the hardware (CPU). This technique requires the use of PyPy which is an alternative to the CPython implementation, the standard that ships with Python from Python.org.
Other languages have arrangements similar to those of PyPy. Java's bytecode compiler produces bytecode which is converted by the Java Virtual Machine (JVM) into native code that is run on the local CPU architecture. The C# language, part of .NET, uses bytecode which is converted by the Common Language Runtime (CLR) into native code that is run on the local CPU architecture. The .NET bytecode was known as Microsoft Intermediate Language (MSIL). However, Microsoft now refers to the .NET bytecode as Common Intermediate Language (CIL). JavaScript and PHP have similar interpreter dependencies. Although, with Google's V8 as mentioned below, JavaScript can be compiled directly from source to machine and thereby skipping the intermediate bytecode step.
There is yet another point to consider. JIT compilation can also occur directly from source to machine and thereby skipping the bytecode generation step. Bytecode processing is generally considered to be faster than direct JIT compilation from source code to machine code due to the work required by the later process. However, there are implementations such as Google's V8 engine which skip the bytecode compilation and compiles source code directly into machine code. Google maintains that V8 incurs little if any performance penalty by translating directly from source to machine code.
Let's look at a brief example of bytecode generation. Code the examples to demonstrate the concepts for yourself. After you obtain more skill with and understanding of Python you may want to come back and experiment with this concept.
The intent of the next four images is to show the bytecode of a simple program. The simple program is shown in module_test.py. That module only contains two lines, the function header and a print statement.

In show_bytecode.py, line 1 imports the 'dis' (short for disassembler) module so it can be used on line 7. On line 2 the simple program named module_test is imported so it can also be used. On line 7, module_test is disassembled which produces the output in the 'Disassembly of module_test' image.
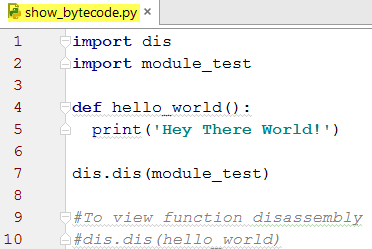
This is the output of running show_bytecode.py. The bytecode names (a.k.a opnames) are in the third column: LOAD_GLOBAL, LOAD_CONST, etc. LOAD_GLOBAL is loading the built-in function print() that is on line 2 of module_test.py. LOAD_CONST is loading the string '\nHello...\n' also from line 2. The numbers next to the bytecodes are address locations on the stack. Recall discussions about the stack and heap in the Variables chapter.

Note that Python creates a .pyc file for module_test.py as a result of the import of module_test in show_bytecode.py. The .pyc file contains the bytecode shown in the disassembly of module_test. A disassembler like the dis module used above is required to read .pyc files.

Some other examples of bytecode opnames are: BINARY_MULTIPLY, UNARY_NOT, and LOAD_FAST. See this link for more on Python bytecodes. More on the Disassembler.
Assembly code - A symbolic language that is more succinct than high-level languages and usually corresponds very closely to machine instructions for the CPU. It uses instructions that consist of operators and operands. For instance, the instruction: 'ADD eax, 20h' means to add 20h (32 decimal) to the value in the register eax and store the result in that register. ADD is the operator. eax and 20 are the operands. Assembly code is converted by an 'assembler' (a utility program) into executable machine code. Dissassembly is the process of converting machine, or low-level code, back into assembly language instructions.
In naming the operators, assembly code uses 'mnemonic devices' (a.k.a. memory aides) to remember the purpose of the instructions. For example, ADD, MOV, SUB, JMP, POP, and PUSH are all assembly codes. In Python, the bytecode mnemonics are similar to assembly code. There is an important difference between Python bytecode and assembly code. The Python interpreter, the consumer of the bytecode, is 'stack-based' and does not use registers but stores all objects on the stack. Whereas, CPUs running assembly code use memory locations and CPU registers and cache for temporary storage. Storage in CPU registers and cache is extremely fast. See the excerpt below from Wikipedia.
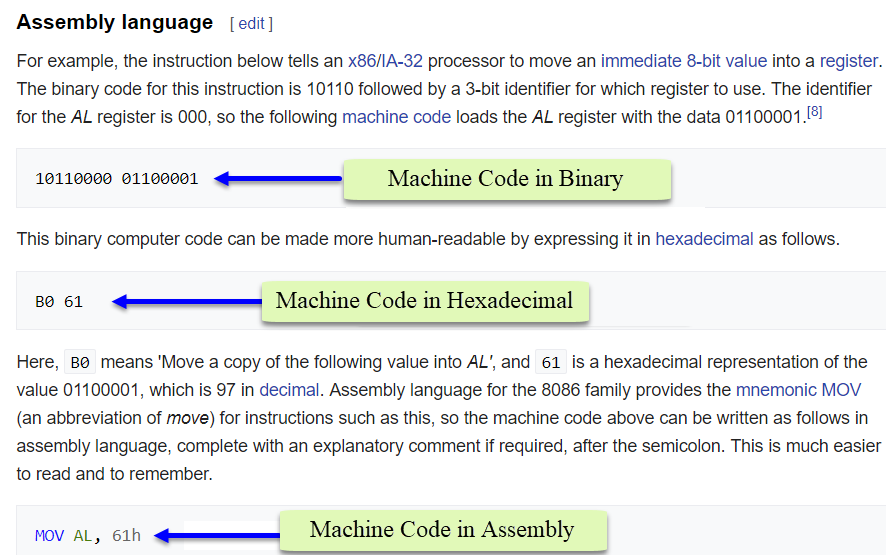
Data Access Times:
- Hard drives - milliseconds - 10-3
- RAM - microseconds - 10-6
- CPU Registers and cache - nanoseconds - 10-9
Opcode - This is short for operation code. It is a short number (in hexadecimal format) used to identify a particular assembly code (or bytecode) operation like MOV, JMP, or ADD. Here are some sample Python opcodes: 01h for POP_TOP, 17h for BINARY_ADD, and 1Eh for SLICE. Note: Some online sources refer to the mnemonics as the opcode and not the numerical identifier. However, the formal specification is: opcode is numerical and opname is the character-based mnemonic. The opcode and the opname are two different ways of referring to the bytecode. See this link for a list of Python opcodes.
Object code - This is not to be confused with object oriented programming which is covered in a later chapter. Object code is a portion of machine code produced from the source code by some compilers. Object code is machine code that has not yet been linked with other library files that are required for a complete program. Usually, as part of the compilation process, object files (.obj) are produced from the program code and are then 'linked' with library files (.lib) to produce the machine-level executable (.exe) file. Use of object files is common with C and C++. Python does not typically produce or work with object files.
Machine code - Often considered the binary language executed on the CPU (Central Processing Unit). These are the 1's and 0's processed directly by the CPU. It is also often shown using hexadecimal numbers such as: C9 4F D7. The hexadecimal numbers have the same 'values' as the binary numbers but are just a different representation. For example, 1111 = F, 1001 = 9, and 1011 = B.
Machine code has another definition which is likely more applicable to software development than simply 1's and 0's. Notice the Machine Code examples in the image above. According to Wikipedia, "Machine code or machine language is a set of instructions executed directly by a computer's CPU." In this second context, machine code is code that can be directly executed by the CPU. Meaning, the code is written with instructions directly understood by the CPU and no additional translation or interpretation is required. For instance, MOV ecx, s1 and ADD eax, ebx are examples of CPU-level instructions and are therefore machine code.
Native code - The term native in the computing context means code that is 'local' to a particular machine written in instructions designed specifically for that CPU, using an instruction set specific to that CPU. It is the lowest level code that can be run on a machine and requires no additional supporting software.
Compiled v. Interpreted Languages
One of the first attributes discussed about any modern computing language is whether it is compiled or interpreted. In the early days of computing, those terms were more succinct and well-defined. More recently, many languages have a mixture of compiled and interpreted aspects which can blur the definitional lines. Furthermore, a compiler or interpreter can be (and probably has been) constructed for any language.
Traditional Compilers - These are also known as ahead-of-time (AOT) compilers since the operation occurs prior to runtime. Thus traditional compilation occurs at 'compile time' and not at runtime like JIT compilers. Traditional compilers are those compilers that produce stand-alone executables (.exe a.k.a machine code) from source code. The compilation process only has to run once to produce the .exe. After the .exe is produced, that file can be run directly by double-clicking it or from the run prompt or the command line.
The .exe file produced by a traditional compiler can be run on a specific platform (i.e. operating system and/or architecture). This means that a .exe file compiled on a Windows machine can be copied to any Windows machine with the same class of operating system/architecture and the .exe will run on that machine. A .exe compiled on an OS X machine will run on any OS X machine. A .exe compiled on a Linux machine will run on Linux machines with the same class of operating system. Unlike Java, .NET, and Python programs, no additional runtime environment is required to run .exe's produced by traditional compilers.
Traditional compilers are also known as static compilers since the compilation process happens entirely before and independently of runtime. Some of the statically compiled languages are: Ada, C, C++, COBOL, Fortran, and Lisp. These compilers produce faster code than JIT compilers since traditional compilers are also designed to optimize code.
Bytecode Compilers - These compilers convert source code into bytecode. That bytecode is then processed by either an interpreter (line-by-line) or a JIT compiler (in many sections or rarely in whole programs). JIT compilers convert the bytecode into machine language (a.k.a. machine code) which can then be run natively on the CPU. JIT compilers may be faster than interpreters since the compilation to machine code is done in bulk with JIT compilers. Interpreters perform line-by-line software interpretation of bytecode or sometimes even source code as in the case of Google's V8 JavaScript engine.
In the case of Python, the bytecode compiler stores bytecode in memory and the interpreter runs the bytecode into machine code and runs it line-by-line. If the program imports modules, the bytecode compiler stores the bytecode in a .pyc file. See the chapter 'Introduction to Python' for more on .pyc file creation.
JIT (Just in Time) Compilers - These compilers convert bytecode to machine code at runtime which is why they are known as JIT compilers. The first time a program is run, that compilation process occurs (usually on sections of the code). However, once converted from bytecode to machine code, that file is stored and additional compilations are not required unless the source code or bytecode is changed.
As previously stated, JIT compilation systems are typically faster than interpreters, especially when working with large programs. However, traditionally compiled programs are still faster than JIT compiled programs since the former are designed to optimize code. Optimization during traditional compilation may require substantial time but that is usually considered an acceptable price to pay for the improved performance when running the executable.
JIT compilers are also known as dynamic compilers since the compilation process occurs at runtime (at least the first time). Some of the dynamically compiled languages are: C#, Java, JavaScript, Python, PHP, Ruby, and VB.NET.
Interpreters - Originally, an interpreter compiled source code directly line-by-line and ran the instructions line-by-line. BASIC and Smalltalk were early interpreted languages that used this approach. However, most modern interpreted languages like Python, use a bytecode complier to first produce bytecode that is then processed by a Virtual Machine (VM, a.k.a. interpreter, runtime). A VM emulates a physical machine (the computer) and is essentially a program to run the Python program.
The Python interpreter is commonly known as the PVM. However, to be more precise, interpreters perform more complex analysis than virtual machines. Interpreters operate on dynamically-typed languages which require type determination at runtime. Whereas, virtual machines work with statically-typed languages and therefore do not have to determine type at runtime.
As it applies to Python, the bytecode compiler generates code objects which contain bytecode. The PVM interprets the bytecode line-by-line. For programs without import statements, the bytecode compiler performs the translation to bytecode and stores the result in memory.
On the other hand, for programs with an import statement, the bytecode compiler is used to produce a bytecode file and the PVM reads the bytecode from that file instead of from memory. In Python, the bytecode files have a .pyc extension. In Java, the bytecode extension is .class and in .NET it is .exe. In the case of Java and .NET, the virtual machines in those languages contain and use a JIT compiler as described above.
Python, the bytecode compiler, and the interpreter (PVM) are also covered in the Introduction to Python chapter.
Some examples of interpreted languages include: JavaScript, PHP, Python, and Ruby.
Combinations and Variations - It should be noted that most languages can be either compiled or interpreted. That is, at least as an academic exercise, compilers have been produced for languages that are generally considered interpreted. And, interpreters have been written for languages that are traditionally compiled. Therefore, whether a language is compiled or interpreted is, strictly speaking, dependent on the particular implementation.