

Introduction to Python
Foreword
Python is a high-level, dynamically-typed, strongly-typed, multi-paradigm, function-level scoped, open source, interpreted computer programming language. Each of the attributes will be discussed below and some are covered more thoroughly in upcoming chapters. We also take a closer look at the opcodes and opnames of bytecodes.
Attributes of Python
High-level Language - The language approximates or is not far from standard English language. An example of an intermediate-level language is assembly language. The lowest level language is machine code which is expressed in either 1's and 0's or hexadecimal number systems.
Dynamically-typed - Object/variable type is not determined until runtime. Determining type at runtime requires additional CPU cycles and therefore will have at least some degree of performance (time) cost. Dynamically-typed languages include JavaScript, Lisp, Objective-C, Perl, PHP, Python, Ruby, and Smalltalk. With statically-typed languages such as C, C++, C#, COBOL, Fortran, and Java, variable type is determined at compile-time (before the program is run).
Strongly-typed - This is an aspect of type safety in which object/variable type is enforced. For example, arithmetic operations cannot be performed with the string value of seven "7", it must be converted to a number first. Strongly-typed languages include: C, C++, C#, Java, Python, Ruby, Smalltalk. With weakly-typed languages (a.k.a. loosely-typed), object/variable type is not enforced and the language attempts to perform operations based on type guesses made at runtime. Naturally, CPU cycles are required to perform the runtime analysis, thus inflicting at least some degree of time cost. Examples of weakly-typed languages include JavaScript and PHP.
Multi-paradigm - Python programs can be written with using three different design approaches. The programs can be procedural which consists of a series of instructions that perform operations on input data. Using the procedural paradigm, the developer deconstructs the 'problem or programming challenge' into a collection of variables, data structures, and procedures. Classical procedural languages include: C, Fortran, Pascal, and BASIC.
It is important to note that the procedural paradigm was preceded by structured programming which is defined by the Structured Program Theorem.
Object-orientation (OO) is currently the predominant approach. Objects contain two things, functionality and data, and sometimes other objects. The objects store data (state) and they also contain functionality to manipulate the data. To be considered object-oriented, a language must support three concepts: encapsulation, inheritance, and polymorphism. These topics are reviewed in the OO chapter. Smalltalk and Java are object-oriented languages in which any program of consequence must be written using OO principles. Python and C++ both support OO but can be written using procedural or functional approaches also. HTML and JavaScript use the browser and document object models for front-end web development.
In functional programming, the focus is on the function. Functions are considered first class citizens which means all operations available to other programming entities are also available to functions. These operations generally include being passed as an argument in another function or method call, being the return value of a function, and being assigned to a variable which enables use for reference elsewhere in the program as a variable. Pure functional languages are those in which functions produce no side effects which modify state or make other changes that are not included as part of the function's return value. Haskell is the most used pure functional language. This is a partial list of other languages (impure) that support functional programming: C++(>=v11), C#, Groovy, Java (>=v8), Lisp, Python, and Ruby.
Note: Both procedural and functional programming were derived from the structural programming paradigm. Structured programming was proposed to combat spaghetti code in which instructions have little-to-no organization. The tenants of structural programming prescribe the use of subroutines (procedures/functions), block structures, and controlled loops in an effort to enhance design, robustness, readability, and maintainability.
Function-level scoped - Variables in Python have function-level scope which means that variables are visible within functions in which the variables are defined. If a variable in Python is not in a function, it is visible within the entire module. Other languages like C++, C#, and Java have block-level scope. Python, PHP, and JavaScript use function-level scope.
Open-source - Software (and other intellectual property) that the developer has made available to the public to share, copy, modify, and/or use for any purpose. This is in contrast to proprietary software that is protected by copyright and cannot be distributed without the copyright holder's permission.
Interpreted - Python is an interpreted language but also uses a bytecode compiler (see the graphic below). When a Python program executes, a bytecode compiler translates source code into bytecode and stores the bytecode in memory. However, if an import is included in the program, a bytecode compiler may be invoked to translate source code into bytecode files (.pyc). See the "How Python Works" section below for more on this topic.
After the bytecode is produced, it is then processed by the PVM (Python Virtual Machine a.k.a runtime, a.k.a. interpreter). This process involves bulk production of bytecode by the bytecode compiler and then line-by-line execution of the bytecode by the PVM.
CPython is the default implementation (interpreter and supporting environment) that is available at python.org. Although, if PyPy (an alternative version of Python) is installed instead of the CPython implementation, then a JIT compiler converts the bytecode to machine code which is much faster than the line-by-line interpretation of the PVM. The compiled file produced by a JIT compiler can be saved for future program executions.
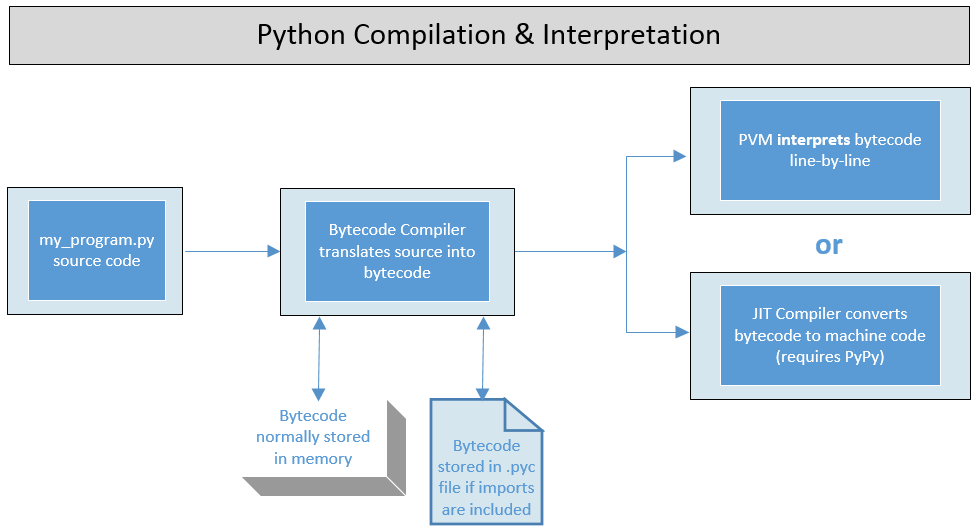
How Python Works: Compiled & Interpreted
Python scripts are not normally converted into bytecode files unless importing a module. Instead, the bytecode compiler stores the bytecode in memory and the interpreter processes the bytecode line-by-line and runs each instruction as it is encountered.
However, compilation to bytecode files can be forced by the compileall technique shown below. The bytecode for each .py file will be placed in a .pyc file in the __pycache__ directory. If a __pycache__ directory does not exist prior to running the compileall command, the directory will be created.
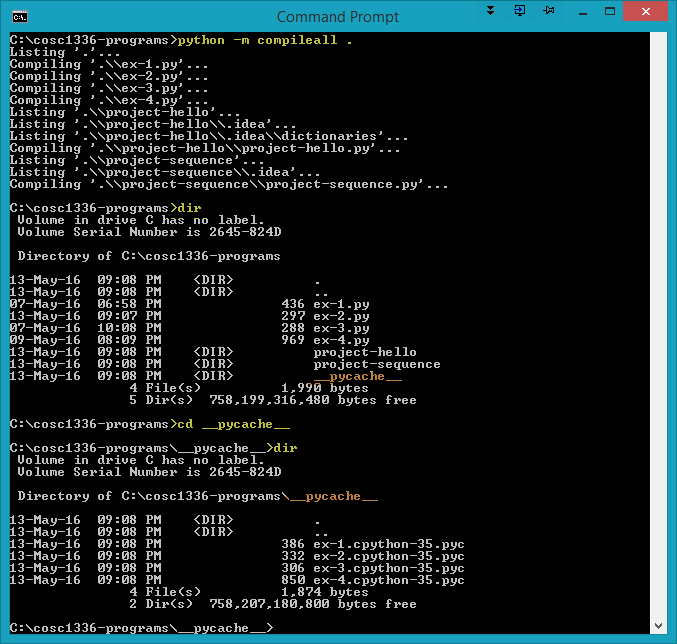
See the __pycache__ directory that was created and the .pyc files for each of the .py files in the cosc1336-projects directory. The .pyc files contain bytecode that corresponds to the source code in the .py files. It is interesting to note that programs run from .pyc files don't run faster than those run from .py files. However, the .pyc files do load faster and therefore there may be a loading performance benefit for large programs which import multiple modules.
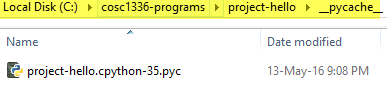
The compileall command is recursive which means it operates on the directories that are within the cosc1336-programs directory where the command was run. Thus, a __pycache__ directory is created for each of the project-hello and project-sequence directories. The project-hello __pycache__ directory is shown below.
Inspecting Bytecode: Opcodes and Opnames
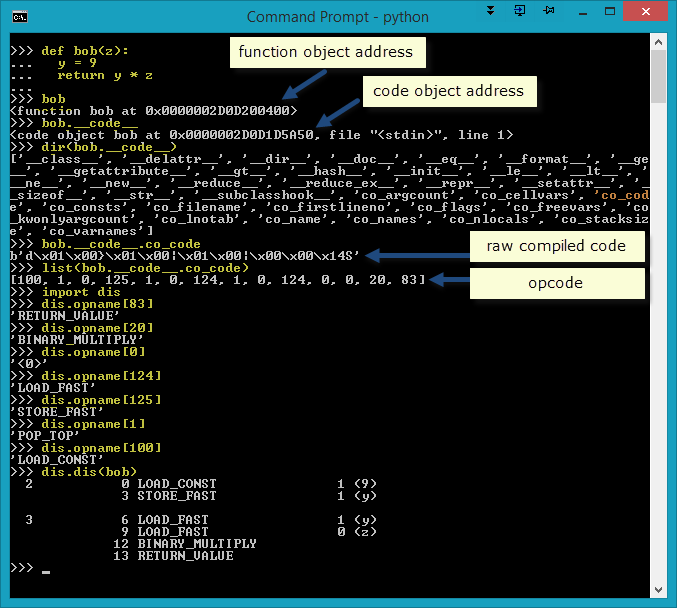
Inspecting bytecode is not a typical part of a Python developer's workflow. However, we take a closer look at Python internals to learn a bit more about the language. In the image below we begin by defining the function 'bob()' which creates both a function object and a code object. Notice that the function object and code object are different and are stored at different addresses (0x0...400 and 0x0...A50). The dir command is used to return a list of valid attributes of that object. We are currently interested in the '__code__' object. Notice the 'co_code' attribute (of the __code__ object) that is highlighted on the right side of the output. That attribute is displayed on the next line: 'bob.__code__.co_code'. That returns a string of raw compiled code: 'd\x01\x00}...'. To see the opcode of the raw compiled code we use the list() function and the opcodes as shown.
Before viewing the opnames from the opcodes we need to import the 'dis' module. The dis module contains a 'disassembler' which translates the opcodes in the __code__ object to human readable opnames.
Now, to see the opnames from the opcodes we use the opname[] sequence (more on this later). For instance, RETURN_VALUE is the opname of the opcode '83'. Finally, we use dis.dis(b0b) to see a more full and human readable listing of the bytesource object. This produces output similar to a Assembly language. A bytesource can be either a module, class, method, function, or code object. In this case, we passed the function 'bob' as the argument. See this for more information on the disassembler.
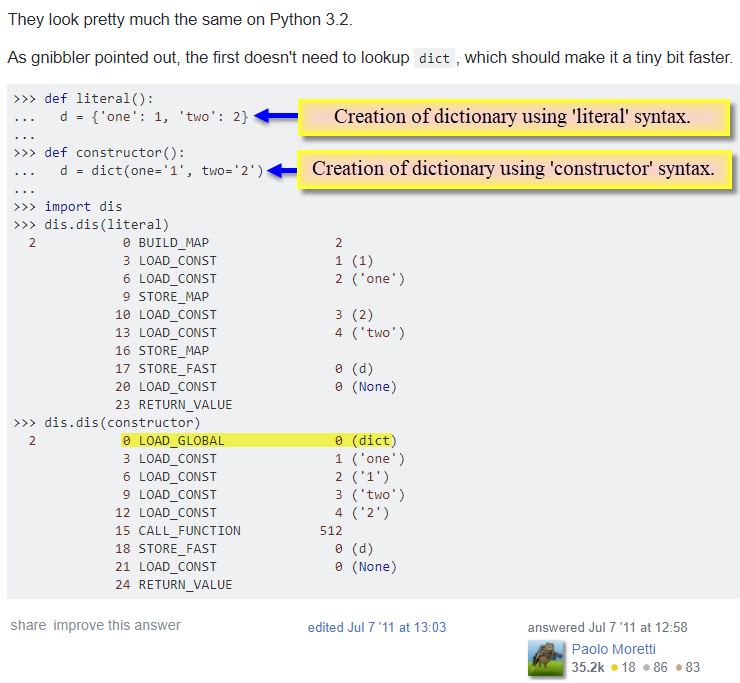
Example Use of the Disassembler on Stack Overflow
Here's an example of a developer using the Python disassembler to answer a question submitted to the forum. The question was, "Is it faster to create a Python dictionary via literal or constructor syntax." While use of the disassembler may not be in the typical Python developer's daily workflow, it is a powerful tool to understand and is indispensable for system-level developers. See Paolo used the disassembler to answer the question.
Future of Python
Hmmm... Who knows? Is that a good answer? Perhaps not. However, it can reasonably be applied to the "Future of _____" question relating to any modern computing technology. Today's hot language may be tomorrow's "Oh yea, that guy." So, what's an aspiring, conscientious, and hard-working developer to do? My personal answer is to continue to aspire, be conscientious, and work hard. In software development, and especially in web development, the suite of alternatives is ever expanding. The approach that works for me is a combination of the following:
- Read newsletters, blogs, and textbooks
- Consume technical podcasts and screencasts
- Attend conferences and workshops (budget permitting)
- Participate in webinars produced by major tech companies
- Review conference lectures made available online after the events
- Be a flexible technician, ready and willing to learn and change as required
- Etc.
Regarding the choice of technology to study... First, choose what you might need on an upcoming project. Just-in-time skill 'leveling-up' is a powerful and effective strategy. It has the benefit of at least applicable urgency and timely relevance. Second, study new technologies that are of interest to you. Interesting projects are more meaningful and memorable. Third, if not applied to an active project, develop a proof-of-concept prototype using new technologies to address a real need (again, preferably something of interest to you).
Years ago, developers could more comfortably become an expert in one language and make a career based on that expertise. In the second decade of the 21st century, that strategy is less assured. Personally, I believe a more advisable strategy is to:
- Acquire a solid foundation in programming
- Become an expert with one or two languages
- Continue to enthusiastically learn new technologies
Being enthusiastic and nimble will enable you to remain technically relevant as the programming landscape continues to evolve.